Machine Learning vs. Deep Learning: What is the Difference in 2026?

Contents
- The Nesting Doll: How AI, ML, and DL Relate to Each Other
- What is Machine Learning? AI Basics for Beginners
- The Core Idea
- The Role of Feature Engineering
- What Machine Learning Looks Like in Practice
- What is Deep Learning? The Neural Network Revolution
- The Core Idea
- Why "Unstructured Data" Changes Everything
- The Cost of That Power
- Machine Learning vs. Deep Learning 2026: The At-a-Glance Comparison
- Real-World Examples: Seeing the Difference in Action
- Everyday Machine Learning
- Everyday Deep Learning
- AI Basics for Beginners: Which One Should You Learn First?
- Mumbai's Job Market: What Employers Are Actually Paying For
- The Foundation Layer: ML is Still the Core
- The Premium Layer: Deep Tech and GenAI is Where the Salary Premium Lives
- The Common Misconceptions, Cleared Up
- Machine Learning vs. Deep Learning 2026: Your Learning Roadmap
- Stage 1: Python and Data Foundations (Months 1–2)
- Stage 2: Machine Learning Foundations (Months 3–5)
- Stage 3: Deep Learning Foundations (Months 6–8)
- Stage 4: Specialisation and Market Entry (Months 9–12)
- Begin Both Worlds: Your Next Step
If you have spent any time reading about AI, you have almost certainly seen the terms "Machine Learning" and "Deep Learning" used in the same breath — sometimes interchangeably, as though they mean the same thing. They do not. Understanding the machine learning vs deep learning 2026 distinction is not just an academic exercise. It is the foundation of every career decision, every course selection, and every job description in the AI field. Get it wrong and you spend months learning the wrong thing for the role you actually want.
This guide explains the difference clearly, from first principles, with no assumed technical background. By the end, you will know what each field is, when each is used, what hardware and data each requires, and — critically — what Mumbai's 2026 AI job market is actually paying for.
Let us start with the picture that makes everything else click.

The Nesting Doll: How AI, ML, and DL Relate to Each Other
The single most useful mental model for understanding these fields is a set of nesting dolls — the Russian matryoshka kind, where each doll sits inside a larger one.
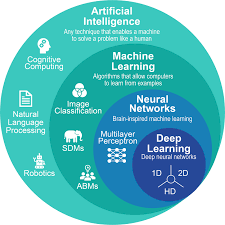
The outermost doll is Artificial Intelligence (AI). AI is the broadest idea: any technique that enables machines to simulate human-like intelligence. This umbrella includes everything from a simple rule-based chatbot that responds "Your order has been shipped" to a system that writes poetry, diagnoses cancer from an X-ray, or drives a car. AI is the destination — the what we are trying to build.
The middle doll is Machine Learning (ML). Machine Learning is one approach to building AI — specifically, the approach of giving machines access to data and letting them learn patterns from that data, rather than explicitly programming every rule. Not all AI is Machine Learning (a chess program that uses hard-coded rules is AI but not ML), but most modern AI is. ML is the how we most commonly build AI today.
The innermost doll is Deep Learning (DL). Deep Learning is one type of Machine Learning — specifically, Machine Learning that uses a particular architecture called a neural network, which is loosely inspired by how neurons in the human brain connect and communicate. Not all Machine Learning is Deep Learning (a decision tree is ML but not DL), but Deep Learning is responsible for the most dramatic AI breakthroughs of the last decade: image recognition, voice assistants, and large language models like ChatGPT.
The hierarchy is clean: all Deep Learning is Machine Learning, and all Machine Learning is AI — but not the other way around.
Everything else in this guide builds on this one picture.
What is Machine Learning? AI Basics for Beginners
The Core Idea
Traditional software works by following rules a programmer explicitly writes. If a user enters a wrong password three times, lock the account. If the temperature exceeds 100°C, trigger the alarm. The programmer anticipated the situation and wrote an instruction for it.
Machine Learning flips this. Instead of writing rules, you give the machine a large collection of examples — data — and the machine figures out the rules itself by finding patterns in that data.
A spam filter built the traditional way would need a programmer to manually list every spammy phrase: "Congratulations, you have won," "Click here to claim your prize," "Limited time offer." Inevitably, spammers would find workarounds. A Machine Learning spam filter instead looks at thousands of emails that humans have already labelled "spam" or "not spam," learns the patterns that distinguish them — word choice, sender behaviour, link density, sending time — and applies those patterns to new emails it has never seen before.
The machine learned the rules from the data. The programmer did not write them.
The Role of Feature Engineering
Machine Learning works best with structured data — data that is organised into rows and columns, like a spreadsheet or a SQL table. Customer age, transaction amount, account balance, number of login attempts, days since last purchase. Each of these is a feature — a measurable property that the ML algorithm uses to make predictions.
Here is the important nuance: in most traditional ML, a human expert has to decide which features to include and how to represent them. This process is called feature engineering, and it is where significant human expertise is required.
A data scientist building a loan default prediction model has to decide: should we include the applicant's monthly income? Their debt-to-income ratio? Their employment duration? Should we create a new feature that combines income and existing debt? The quality of these decisions dramatically affects the model's performance.
This is what people mean when they say ML requires "human guidance" — not that humans make the predictions, but that humans shape the input that the algorithm learns from. The algorithm learns the patterns; the human decides what patterns to look for.
What Machine Learning Looks Like in Practice
A Machine Learning workflow typically looks like this:
- Collect and clean data — pull historical examples from a database, fix missing values, remove duplicates
- Feature engineering — decide which columns to use, create new derived features, encode categorical variables
- Choose and train a model — a decision tree, a random forest, a gradient boosting model, a linear regression
- Evaluate the model — check its accuracy on data it has not seen before
- Deploy the model — put it into production so it can make predictions on new, real-world inputs
The entire process can run on a standard laptop for most ML problems. The data is structured and tabular. The models are mathematically interpretable — you can often examine what a decision tree decided and understand why. This interpretability is one of ML's significant advantages in regulated industries like banking and insurance, where a model's decisions may need to be explained to regulators.
What is Deep Learning? The Neural Network Revolution
The Core Idea
Deep Learning is Machine Learning that uses neural networks — architectures loosely inspired by the structure of the human brain. Just as the brain consists of billions of neurons connected by synapses that strengthen with use, a neural network consists of layers of artificial neurons connected by weights that are adjusted during training.
The "deep" in Deep Learning refers to the number of layers in these networks. A shallow neural network might have one or two layers. A deep neural network — used for image recognition, voice processing, or language understanding — might have dozens or hundreds of layers, each one extracting increasingly abstract features from the input.
What makes this powerful is that the network learns its own features. You do not tell it what to look for. You feed it raw, unstructured data — the pixels of an image, the waveform of a sound file, the sequence of words in a sentence — and the network figures out, through millions of training iterations, which low-level patterns (edges, phonemes, word relationships) combine into high-level meanings (face, spoken word, intent).
This is the fundamental difference from traditional Machine Learning: in ML, humans engineer the features; in DL, the network engineers them automatically.
Why "Unstructured Data" Changes Everything
Consider what you would need to do to feed a photograph into a traditional ML model. A photograph is not a spreadsheet. It is a grid of millions of pixels, each with three colour values. To use traditional ML, you would need to manually extract features: "Is there a circle shape?" "Is the dominant colour in this region pink?" "Is the aspect ratio square?" This manual feature extraction for images, audio, and text is extraordinarily difficult and limits the complexity of problems traditional ML can solve.
Deep Learning removes this bottleneck. You feed the raw pixels directly into a convolutional neural network (CNN), and the network — given enough data and training time — learns to recognise eyes, then faces, then emotions, then identities, without any human telling it that eyes have a specific shape.
This is why Deep Learning dominates tasks involving:
- Images: Photo classification, medical image analysis, quality control in manufacturing
- Audio: Voice recognition (Siri, Google Assistant), music generation, speaker identification
- Text and Language: Sentiment analysis, translation, summarisation, and the large language models (ChatGPT, Claude, Gemini) that have transformed how people interact with computers
- Video: Object detection, activity recognition, autonomous vehicle perception
The Cost of That Power
Deep Learning's ability to learn from raw, unstructured data comes with significant requirements that traditional ML does not have:
Massive amounts of data. A decision tree might learn from a few thousand labelled examples. A deep learning model for image recognition might need millions. A large language model is trained on essentially the entire written internet. Without large volumes of training data, deep neural networks do not converge — they simply memorise the small dataset they have without learning anything generalisable.
Significant computational power. The matrix multiplications involved in training deep neural networks are astronomically expensive by traditional computing standards. A small ML model might train in seconds on a CPU. A large deep learning model can take weeks on clusters of NVIDIA GPUs — specifically the Tensor Cores that are optimised for the parallel arithmetic deep learning requires. The compute cost for training a large language model runs to millions of dollars in cloud GPU time.
Reduced interpretability. When a deep learning model makes a decision — "this loan application should be rejected" or "this image contains a tumour" — it is extremely difficult to explain why it made that decision. The model's reasoning is distributed across millions of weights in hundreds of layers. This "black box" nature is a significant challenge in regulated industries where explainability is legally required.
Machine Learning vs. Deep Learning 2026: The At-a-Glance Comparison
| Dimension | Machine Learning | Deep Learning |
|---|---|---|
| Data type | Structured (tables, spreadsheets, SQL) | Unstructured (images, audio, text, video) |
| Data volume needed | Hundreds to tens of thousands of examples | Millions of examples (often) |
| Hardware required | Standard laptop or CPU server | NVIDIA GPU clusters (Tensor Cores) |
| Feature engineering | Required — humans select and craft features | Largely automatic — network learns features |
| Interpretability | High — decision trees, regression are explainable | Low — neural networks are "black boxes" |
| Training time | Minutes to hours | Hours to weeks (for large models) |
| Best for | Tabular data, business analytics, forecasting | Images, audio, language, complex pattern recognition |
| Entry-level tools | scikit-learn, XGBoost, pandas | TensorFlow, PyTorch, Keras |
| Example algorithms | Random Forest, Gradient Boosting, SVM, Logistic Regression | CNN, RNN, LSTM, Transformer |
Real-World Examples: Seeing the Difference in Action
The fastest way to make this distinction concrete is through examples you have already encountered.
Everyday Machine Learning
Email spam filters (Gmail, Outlook) use ML to classify incoming messages as spam or not-spam based on structured features: sender reputation, word frequency, link count, formatting patterns. The training data is labelled emails; the features are engineered properties of those emails. Your spam filter is not "thinking" — it is applying statistical patterns learned from millions of examples.
Stock price and demand forecasting at companies like Reliance, Tata, or any Mumbai commodities trader uses ML models trained on historical price data, trading volume, macroeconomic indicators, and seasonal patterns. The inputs are structured numbers; the output is a predicted value. Gradient boosting models and linear regression dominate here.
Netflix and Amazon recommendations are powered by collaborative filtering and matrix factorisation — classic ML techniques that find patterns in structured user-item interaction data ("users who liked X also liked Y") to predict what any given user will enjoy next.
Credit risk scoring at HDFC or ICICI Bank uses ML models trained on structured customer data — income, employment history, existing credit, repayment track record — to predict the probability of loan default. The model's output is a score; the inputs are a spreadsheet row.
Everyday Deep Learning
ChatGPT, Claude, and other Large Language Models are the most visible Deep Learning systems in the world right now. They are Transformer-based neural networks trained on internet-scale text data — hundreds of billions of words — and they learn the statistical relationships between words with enough depth and nuance to generate coherent, contextually appropriate, and factually grounded text responses.
Self-driving car perception systems (Tesla Autopilot, Waymo) use convolutional neural networks to process camera, radar, and lidar input in real time — identifying pedestrians, reading traffic signs, detecting lane markings, predicting the movement of other vehicles. No human engineer could manually specify the features to look for across all lighting conditions, weather states, and road configurations. The network learns them.
Face recognition — from the Face ID on your iPhone to the surveillance systems used at Mumbai's Chhatrapati Shivaji Maharaj International Airport — uses deep convolutional networks trained on millions of face images to create a numerical "embedding" of each face that is unique enough to serve as an identity.
Medical imaging diagnosis — AI systems that detect diabetic retinopathy from eye scans, identify cancerous nodules in chest X-rays, or flag anomalies in MRI scans — are deep learning models trained on radiologist-labelled medical images. Their accuracy in some studies matches or exceeds specialist physicians.
Google Translate and real-time voice assistants process unstructured audio and text through deep neural network pipelines that would be completely intractable with traditional ML approaches.
AI Basics for Beginners: Which One Should You Learn First?
If you are a beginner asking "should I learn ML or DL first?" — the answer is almost always: start with Machine Learning.
Here is why:
The mathematical foundations transfer directly. Linear algebra, probability, statistics, gradient descent, cross-validation — these concepts underpin both ML and DL. Learning them in the context of interpretable, simple ML algorithms (linear regression, decision trees, random forests) builds intuition that makes DL significantly easier to understand later.
The programming tools build in the right order. Proficiency in Python, pandas, NumPy, and scikit-learn — the ML toolkit — is a prerequisite for working effectively with TensorFlow and PyTorch (the DL toolkit). Trying to learn DL without ML foundations is like trying to run before walking.
Most entry-level data roles use ML. The business analytics, MIS reporting, credit risk, and customer analytics roles at Mumbai's banks and BFSI firms that represent the majority of data science hiring in the city use ML more than DL. The skills you build in your first 6–12 months of ML study will get you your first job. DL comes next.
DL is harder to debug without foundations. When a neural network does not converge — when the training loss will not decrease and the model produces garbage outputs — diagnosing the problem requires an understanding of gradient flow, weight initialisation, and learning rate schedules that only makes sense if you already understand gradient descent from simpler models.
The path: Python + Statistics + ML (scikit-learn) → Deep Learning (TensorFlow/PyTorch) → Specialisation (NLP, Computer Vision, GenAI).
Mumbai's Job Market: What Employers Are Actually Paying For
Understanding the technical difference between ML and DL is important. Understanding what Mumbai's market pays for is essential.
The Foundation Layer: ML is Still the Core
The majority of data science and analytics roles at Mumbai's large employers — HDFC Bank's analytics CoE in BKC, ICICI's data science team, Nykaa's business intelligence unit, Fractal Analytics' client delivery teams — are still primarily ML-driven. Structured tabular data from transaction systems, customer databases, and operational logs dominates the actual work. Decision trees, gradient boosting (XGBoost, LightGBM), logistic regression, and clustering are the workhorses of these roles.
For 70–80% of Mumbai's data science job market, strong ML fundamentals — feature engineering, model evaluation, Python, SQL, and the ability to communicate model findings to business stakeholders — are sufficient to be hired, contribute meaningfully, and grow a career.
The Premium Layer: Deep Tech and GenAI is Where the Salary Premium Lives
The remaining 20–30% of roles — and the top-paying decile of compensation — are concentrated in what Mumbai's hiring community calls "Deep Tech": roles that require Deep Learning fluency and increasingly, GenAI integration skills.
These roles are growing fastest and paying the most in Mumbai's 2026 market:
- AI/ML Engineers at FinTech startups (Razorpay, Paytm, BharatPe) building fraud detection systems that process image and behavioural data, not just transaction tables
- NLP Engineers at BFSI and analytics firms building document processing pipelines, customer service automation, and regulatory compliance tools that handle unstructured text at scale
- GenAI Engineers (the role covered extensively in our GenAI Engineer vs. Data Scientist guide) building RAG pipelines, LLM-powered products, and agentic workflows — the field that is currently generating the largest salary premiums in Mumbai
- Computer Vision roles at manufacturing, retail, and healthcare companies building inspection, recognition, and analysis systems
The salary gap is real. A mid-level ML-focused data scientist in Mumbai earns ₹18L–₹25L. A mid-level Deep Learning or GenAI engineer at a comparable experience level earns ₹24L–₹38L. The gap widens at senior levels, where pure Deep Tech expertise in financial applications can reach ₹50L–₹70L+.
The implication is not "ignore ML and jump to DL." It is: build your ML foundation, then deliberately add DL and GenAI skills to access the roles and compensation at the top of the market.
The Common Misconceptions, Cleared Up
"Deep Learning is always better than Machine Learning." No. For structured tabular data — which is the majority of data in BFSI, retail, and operations — gradient boosting models routinely outperform deep learning on prediction accuracy, train faster, require less data, and produce interpretable outputs. Deep Learning is superior for unstructured data; ML is often superior (or equivalent) for structured data.
"You need a PhD to do Deep Learning." No — but you do need mathematical grounding (linear algebra, calculus, statistics) and serious programming skill. These are learnable without a PhD. The barrier is not credentials; it is the investment of time and structured study to build the foundations genuinely rather than superficially.
"Machine Learning is the 'old' version of AI." No. ML encompasses Deep Learning. And many of the most valuable business applications of AI in Mumbai — credit risk, fraud detection, demand forecasting, customer analytics — are best served by traditional ML approaches. ML is not obsolete; it is the right tool for a large class of problems that DL is not.
"ChatGPT uses Machine Learning." Technically yes — it is a subset of ML. But colloquially, when people say "ML" they usually mean traditional ML methods. ChatGPT is specifically a Deep Learning system using the Transformer architecture. This is why precision in these definitions matters: saying "ChatGPT uses ML" is like saying "a Formula 1 car uses internal combustion" — technically true but missing the specificity that matters.
Machine Learning vs. Deep Learning 2026: Your Learning Roadmap
Here is the concrete sequence from beginner to job-ready, calibrated to Mumbai's 2026 market:
Stage 1: Python and Data Foundations (Months 1–2)
- Python fundamentals: data types, functions, control flow, file handling
- NumPy and pandas for data manipulation
- Matplotlib and Seaborn for visualisation
- SQL basics: SELECT, JOIN, GROUP BY, aggregations
Milestone: Can clean a real-world dataset, perform exploratory analysis, and produce a visualisation report.
Stage 2: Machine Learning Foundations (Months 3–5)
- Statistics essentials: probability, distributions, hypothesis testing, correlation
- Supervised learning: linear regression, logistic regression, decision trees, random forests, gradient boosting
- Unsupervised learning: K-means clustering, PCA for dimensionality reduction
- Model evaluation: train-test split, cross-validation, AUC-ROC, precision/recall
- scikit-learn as the primary toolkit
Milestone: Can build, train, evaluate, and interpret an ML model on a structured dataset. Can explain model results to a non-technical stakeholder.
Stage 3: Deep Learning Foundations (Months 6–8)
- Neural network architecture: neurons, layers, activation functions, forward pass, backpropagation
- Convolutional Neural Networks (CNNs) for image tasks
- Recurrent Neural Networks and LSTMs for sequence data
- Transformer architecture basics — the foundation of every modern LLM
- TensorFlow or PyTorch as the primary toolkit
Milestone: Can build and train a CNN for image classification and an LSTM for a time-series forecasting task.
Stage 4: Specialisation and Market Entry (Months 9–12)
Choose one of three specialisation tracks based on your target role:
- NLP and GenAI track: LangChain, LlamaIndex, RAG pipelines, LLM fine-tuning, prompt engineering — targeting GenAI Engineer and NLP Engineer roles at FinTech and BFSI
- Computer Vision track: Advanced CNN architectures (ResNet, EfficientNet), object detection (YOLO), image segmentation — targeting computer vision roles in manufacturing, retail, and healthcare
- ML Engineering track: MLOps, model deployment, cloud platforms (AWS SageMaker, Azure ML), Docker, Airflow — targeting ML Engineer and MLOps roles at scale-oriented firms
Begin Both Worlds: Your Next Step
The distinction between Machine Learning and Deep Learning is the starting point of a journey that, if navigated intentionally, leads to some of the most intellectually engaging and financially rewarding careers available in Mumbai's 2026 technology market.
But the journey from "I understand the difference" to "I have a job offer as a Data Scientist or AI Engineer" requires more than reading guides. It requires structured, project-based learning — with someone who can answer the "why is my model not converging?" and "which algorithm is right for this problem?" questions that articles cannot anticipate.
TechPaathshala's AI Foundation Workshop is the structured starting point for beginners who want to enter both worlds — ML and DL — with a curriculum designed around Mumbai's actual job market, not a generic global syllabus.
In the workshop, you will:
- Build your first ML model from scratch — a credit risk classifier using structured banking data, starting from raw data cleaning through to model evaluation — the kind of project that is directly relevant to Mumbai's BFSI and FinTech employers
- Understand how neural networks actually learn — not just "there are layers of neurons" but how backpropagation adjusts weights, what a loss function is doing, and why a model with high training accuracy and low test accuracy is a problem — so that when you start building deep learning models, you understand what is happening inside them
- Get a personalised roadmap — based on your background, timeline, and target role in Mumbai's data and AI market, mapping the exact sequence of skills from where you are to your first data science or AI engineering offer
- Connect with Mumbai's data community — cohort-based learning with peers from Mumbai's commerce, engineering, and management colleges who are navigating the same transition
The workshop is designed for absolute beginners — no prior programming or statistics experience required. The only prerequisite is the intention to build these skills seriously.
👉 Register for TechPaathshala's AI Foundation Workshop — and take your first step into both Machine Learning and Deep Learning with a clear roadmap and expert guidance from Day 1.
TechPaathshala is a Mumbai-based technology education platform helping students, graduates, and career switchers build AI, data science, and full stack skills — with programmes designed for Mumbai's rapidly evolving technology job market.



